Hemingroth
Contactless interface using gesture recognition
Introduction
The development of intuitive and natural human-computer interfaces (HCIs) is a critical area of research, aiming to bridge the gap between human intention and machine comprehension. Gesture recognition, in particular, offers a promising avenue for creating seamless and engaging user experiences. This project explores the application of Google's MediaPipe, a cross-platform, customizable machine learning (ML) solutions framework, for real-time gesture recognition using device cameras.
MediaPipe provides pre-built ML solutions for various tasks, including hand tracking, pose estimation, and face detection. Specifically, its hand tracking solution leverages advanced techniques to accurately estimate 3D hand landmarks from RGB camera input, facilitating precise gesture analysis. By providing readily available and highly accurate landmark data, MediaPipe simplifies the complex process of gesture interpretation, allowing researchers and developers to focus on higher-level applications.
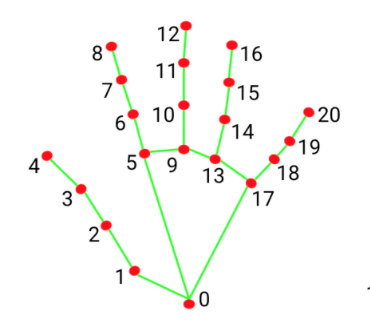
The ability to accurately and efficiently recognize user gestures using readily available camera technology is a fundamental step towards creating more natural and interactive HCIs. Gesture-based interfaces can offer significant advantages over traditional input methods, such as keyboards and mice, particularly in scenarios where physical contact is inconvenient, dangerous, or impossible. By harnessing the power of MediaPipe, we can explore and develop novel gesture-driven applications that enhance user engagement and create more seamless and intuitive connections between humans and machines.
Interface and word sets
The interface for this project was a simple game that asked the user to rearrange a set of randomly ordered letters to spell a common English word. Words of 5 letters are used when playing this game on desktop, and words of 3 letters are used when on a mobile device (to account for the smaller display dimensions).
Word sets were generated by Google Gemini (Flash 2.0) using the prompt in Figure 2. Initially the prompt asked for words to be in all uppercase letters but this resulted in an unacceptable amount of hallucination, which disappeared when words were instead asked for in lowercase.
Give me a list of 70 English words. Every words in the list must meet the following criteria:
- Be exactly 5 letters long (do not include 4 letter words or 6 letter words)
- Should be an everyday word that a child would be familiar with.
- Have the same spelling in British and American English.
Output the words as a JavaScript array. Some examples are shown below.
Correct example:
["books", "water", "house"] // all words meet criteria
Incorrect examples:
["books", "pencil", "house"] // "pencil" is 6 letters long so doesn't meet the criteria
["book", "tried", "house"] // "book" is 4 letters long so doesn't meet the criteriaDebouncing
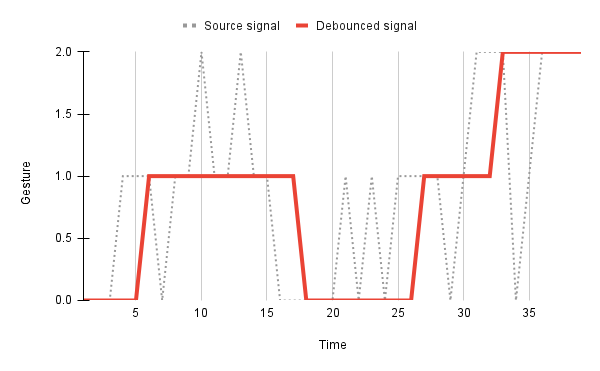
Initially Google MediaPipe would process every frame of the video feed for recognised gestures, which produced a noisy signal. Sometimes the user's hand would be obscured by an object or the device camera would be exposed to glare, resulting in gesture detection momentarily failing. To mitigate this the MediaPipe gesture recognition signal is passed through a 'debouncing' or 'smoothing' function which applies a window to the signal to filter out noise, producing a more stable output.
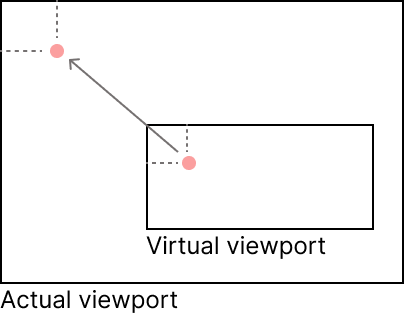
Virtual viewport projection
The accuracy of MediaPipe degrades as the user's hand moves closer to the periphery of the device's camera. Similarly, as the user is asked to control the interface using their right hand it's inconvenient for them to have to move their hand in front of their face to move the cursor towards the left side of the interface. To mitigate these two factors the video feed is cropped down to a virtual viewport, ignoring the margin regions where accuracy is low. Gesture landmarks detected in this more accurate virtual viewport are then scaled out and projected onto the visible interface viewport so that the user is unaware of the cropping.
Conclusion
This project demonstrated the feasibility of utilizing gesture recognition to create an intuitive and natural interface for human-computer interaction within a simple gaming environment. Historically, accessing the computational power of computers has necessitated human adaptation to artificial environments. We have been confined to desks, manipulated keyboards and mice, and navigated complex user interfaces, effectively forcing our natural behaviors to conform to the rigid demands of the machine. However, the advancement of artificial intelligence and related technologies, particularly in areas like computer vision and machine learning, is fundamentally shifting this paradigm. We are now witnessing a transition where the computer adapts to the human, rather than the other way around.
The prototype, while basic, exemplifies this shift. By enabling control of a game through natural hand gestures, it demonstrates how users can engage with computational systems in a more fluid and intuitive manner, freeing them from the constraints of traditional input devices. This represents a step towards a future where computing is seamlessly integrated into our natural environments, allowing us to leverage its benefits without sacrificing our inherent modes of interaction.